关于Greenplum数据库中的冗余和故障切换
关于Greenplum数据库中的冗余和故障切换
这一主题给出了Greenplum数据库高可用性特性的一个高层次的概述。
用户可以利用镜像组件部署一个不会出现单点故障的Greenplum数据库。 下面的小节描述了镜像Greenplum系统主要组件的策略。 更多关于Greenplum高可用特性的详细介绍,请见 Greenplum数据库高可用性概述。
关于Segment镜像
部署Greenplum数据库系统时,可以配置Mirror实例。 Mirror节点可以使当Primary节点宕机的时候,将数据库查询转移到备份节点上。 Mirror节点通过将数据从主节点同步到从节点的事务日志复制进程保持同步。 Mirror机制在生产环境中强烈建议开启,并且是Pivotal支持所必须的。
作为最佳实践,从节点实例必须和主节点部署到不同的机器以防止单机故障带来的影响。 在虚拟化环境下,二级(镜像)Segment必须总是位于一个与主要Segment不同的存储系统上。 在一个为最大化可用性或者主机或者多个主要Segment失效时最小化性能衰退而设计的配置中,镜像Segment可以被分布在集群中剩下的主机上。
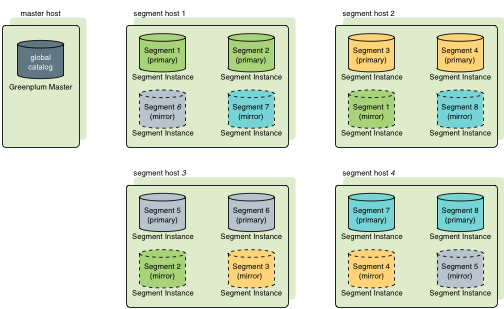
当用户在初始化或者扩展Greenplum系统时,可使用两种标准的镜像配置。默认的配置被称为组镜像, 这种配置会把一个主机上的主要Segment的所有镜像都放置在集群中的其他一台主机上。 还可以用一个命令行选项选择另一种标准配置散布镜像,散布镜像会把每台主机的镜像散布到集群中剩余的主机上并且要求集群中的主机数量比每个主机上的主要Segment数量更多。
Figure 1展示了当配置了散布镜像后,表数据如何分布在Segment之间。
Segment故障切换和恢复
当Greenplum数据库系统中启用了镜像时,系统会在主要Segment变成不可用后自动切换到镜像Segment。 在一个Segment实例或者主机出问题的情况下,只要在剩余的活动Segment上的所有数据可用,Greenplum数据库系统就能保持可操作。
如果Master无法连接到一个Segment实例,它会在Greenplum数据库系统目录中标记该Segment实例为宕机并且把镜像Segment提升起来作为替代。 失效的Segment实例将保持无法操作的状态直到管理员采取措施将它重新恢复上线。 管理员可以在系统运行时恢复失效的Segment。 恢复进程只会复制该Segment无法操作期间错过的更改。
如果用户没有启用镜像,当一个Segment实例变得无效时整个系统将会自动关闭。在继续操作之前,用户必须恢复所有失效的Segment。
关于Master镜像
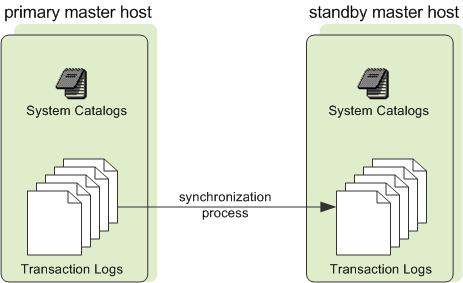
用户也可以选择性地在一台不同于Master节点的主机上部署一个Master实例的备份或者镜像。 在主Master主机变得不可用时,一个备份Master主机将发挥温备的作用。 后备Master利用事务日志复制进程保持与主Master同步,复制进程运行在后备Master上并且负责在主备Master主机之间同步数据。
如果主Master失效,日志复制进程会停止,并且后备Master会被激活以替代它的位置。 这种切换不会自动发生,而是必须由外部触发。 在激活后备Master时,将用已复制的日志来重构Master主机最后一次成功提交时的状态。 被激活的后备Master实际会变成Greenplum数据库的Master,它会在主端口(在Master主机和备份Master主机上必须被设置为相同)上接受客户端连接。
由于Master不包含任何用户数据,只有系统目录表需要在主节点和备份节点之间同步。 当这些表被更新时,更改会被自动地复制到后备Master以确保与主Master的同步。
关于Interconnect冗余
Interconnect指的是Segment之间的进程间通信以及这种通信所依赖的网络设施。 通过在用户的网络上部署双千兆以太网交换机以及到Greenplum数据库主机(Master和Segment)服务器的冗余千兆连接,用户可以得到非常可靠的Interconnect。 处于性能的原因,我们推荐10-Gb以太网或者更快的网络。