使用PXF访问Hadoop
PXF与Cloudera,Hortonworks Data Platform,MapR和通用Apache Hadoop发行版兼容。 PXF安装有HDFS,Hive和HBase连接器。 您可以使用这些连接器从以上Hadoop发行版访问各种格式的数据。
gphdfs 协议的外部表来访问存储在Hadoop中的数据。 Greenplum数据库6.0.0版本移除了gphdfs 协议。 在Greenplum数据库6.x版本中使用PXF和pxf协议外部表来访问Hadoop。架构
HDFS是Apache Hadoop使用的主要分布式存储机制。 当用户或应用程序在引用了HDFS文件的PXF外部表上执行查询时,Greenplum数据库master节点将查询分发给所有的segment节点。 每个Segment实例请求运行在其主机上的PXF代理. 当它从segment实例接受请求时, PXF代理:
- 分配工作线程以处理来自segment实例的请求。
- 调用HDFS Java API从HDFS NameNode请求HDFS文件的元数据信息。
- 提供HDFS NameNode返回的元数据信息给segment实例。
图: PXF-到-Hadoop 架构
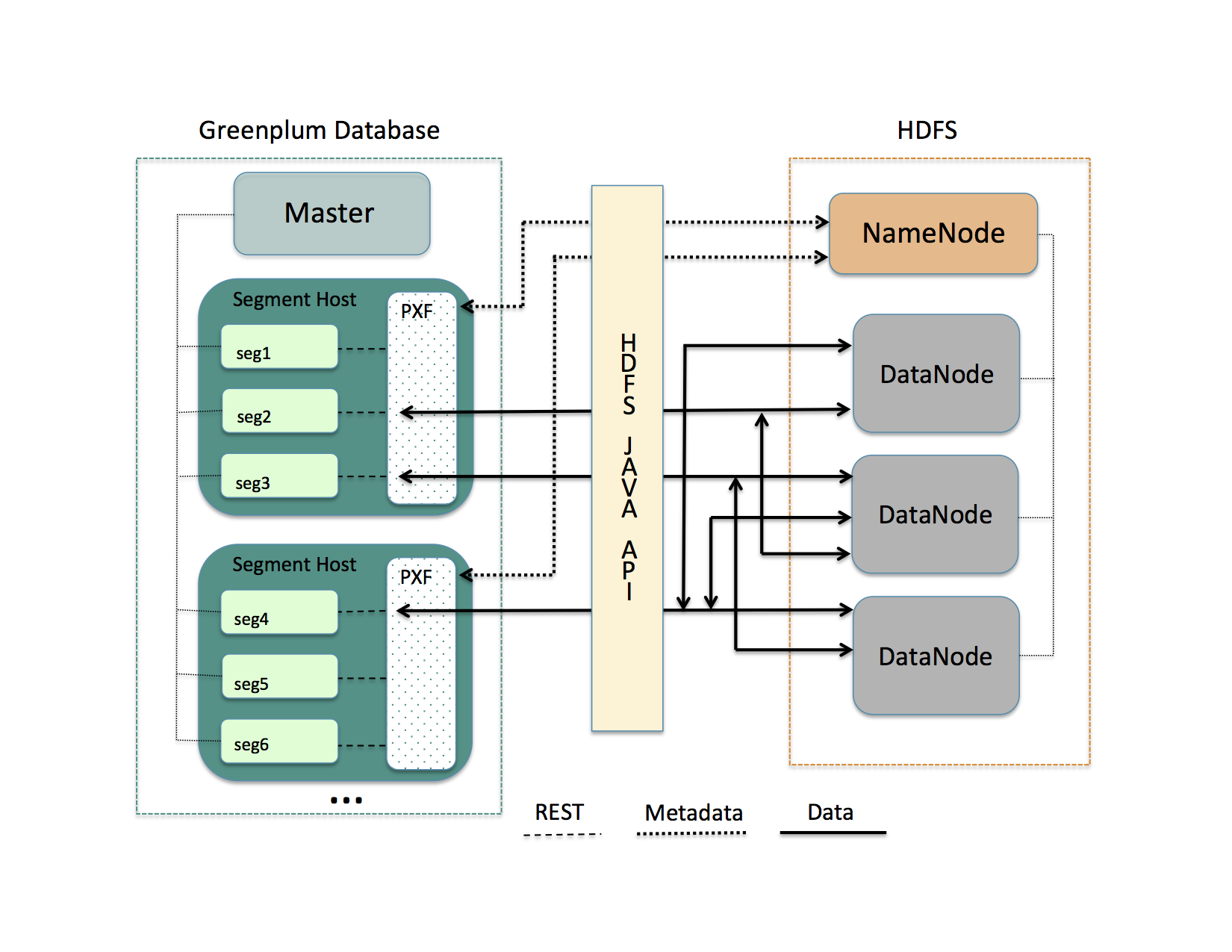
Segment实例使用它在Greenplum数据库中的 gp_segment_id 和元数据描述的文件块信息将查询所需数据的特定部分分配给自己。 然后,segment实例向PXF代理发送请求来读取分配的数据。 该数据可以存储在一个或多个HDSFS数据节点上。
PXF代理调用HDFS Java API来读取数据并将其传递给segment实例。 segment实例将其部分数据传递给Greenplum数据库master节点。 此通信跨segment节点和segment实例并行发生。
先决条件
在使用PXF处理Hadoop数据之前,请确保:
- 您已经配置并初始化PXF, 并且PXF正在每台segment主机上运行. 更多详情,请参阅配置 PXF。
- 您已经配置了计划使用的PXF Hadoop连接器。有关说明,请参阅配置PXF Hadoop 连接器。 如果您计划访问存储在Cloudera Hadoop集群中的JSON格式数据, 则PXF需要Cloudera 5.8或者更高的Hadoop发行版。
- 如果开启了用户模拟(默认), 确保您已将Greenplum数据库外部表需要访问到的HDFS文件及目录的读取(并根据需要写入) 权限,授予给了每个需要访问这些文件和目录的Greenplum数据库用户/角色的名称。 如果未开启用户模拟,您必须要将权限授予给
gpadmin用户。 - Greenplum数据库segment主机和外部Hadoop系统之间的时间是同步的。
HDFS Shell 命令入门
Hadoop包含与HDFS文件系统直接交互的命令行工具。 这些工具支持典型的文件系统操作,包括复制和列出文件,更改文件权限等。
HDFS 文件系统命令语法为hdfs dfs <选项> [<文件>]。 在没有选项的情况下调用,hdfs dfs将列出该工具支持的文件系统选项。
调用hdfs dfs命令的用户必须具有HDFS存储数据的读取权限才能列出和查看目录及文件内容, 并具有写入权限才能创建目录和文件。
PXF Hadoop主题使用的hdfs dfs选项包括:
| 选项 | 描述 |
|---|---|
-cat |
显示文件内容 |
-mkdir |
在HDFS中创建目录 |
-put |
将文件从本地文件系统复制到HDFS中 |
例:
在HDFS中创建目录:
$ hdfs dfs -mkdir -p /data/exampledir
将文本文件从本地文件系统复制到HDFS:
$ hdfs dfs -put /tmp/example.txt /data/exampledir/
显示位于HDFS中的文本文件的内容:
$ hdfs dfs -cat /data/exampledir/example.txt
连接器,数据格式和配置文件
PXF Hadoop连接器提供内置配置文件以支持以下数据格式:
- Text
- Avro
- JSON
- ORC
- Parquet
- RCFile
- SequenceFile
- AvroSequenceFile
PXF Hadoop连接器公开以下配置文件以读取这些支持的数据格式,并在许多情况下写入:
| 数据源 | 数据格式 | 配置文件名称 | 弃用的配置文件名称 |
|---|---|---|---|
| HDFS | 单行的分隔文本 | hdfs:text | HdfsTextSimple |
| HDFS | 含有被双引号引起来的换行符的分隔文本 | hdfs:text:multi | HdfsTextMulti |
| HDFS | Avro | hdfs:avro | Avro |
| HDFS | JSON | hdfs:json | Json |
| HDFS | Parquet | hdfs:parquet | Parquet |
| HDFS | AvroSequenceFile | hdfs:AvroSequenceFile | n/a |
| HDFS | SequenceFile | hdfs:SequenceFile | SequenceWritable |
| Hive | TextFile 存储格式 | Hive, HiveText | n/a |
| Hive | SequenceFile 存储格式 | Hive | n/a |
| Hive | RCFile 存储格式 | Hive, HiveRC | n/a |
| Hive | ORC 存储格式 | Hive, HiveORC, HiveVectorizedORC | n/a |
| Hive | Parquet 存储格式 | Hive | n/a |
| HBase | 任意存储格式 | HBase | n/a |
使用CREATE EXTERNAL TABLE命令指定pxf协议时,提供配置文件名称,以创建引用Hadoop文件、目录或表的Greenplum数据库外部表。例如,以下命令创建一个使用默认服务器的外部表,并指定名为hdfs:text的配置文件:
CREATE EXTERNAL TABLE pxf_hdfs_text(location text, month text, num_orders int, total_sales float8)
LOCATION ('pxf://data/pxf_examples/pxf_hdfs_simple.txt?PROFILE=hdfs:text')
FORMAT 'TEXT' (delimiter=E',');